
現代のAPI監視における重要要件
信頼性は監視から生まれる
2025年3月28日
著者: Gerardo Dada
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Critical Requirements for Modern API Monitoring」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
企業は、APIの停止やパフォーマンス低下によって毎年数百万ドルの損失を被っています。
これらのリスクを軽減するためには、現代的なオブザーバビリティ戦略が不可欠です。
現在、ほぼすべてのシステムがAPIに依存しています。
データ統合、認証、決済処理などの多くの機能は、信頼性と高性能を備えた複数のAPIに依存しています。
世界中の銀行が、決済、信用評価、ローン申請、不正取引の検知などの目的で、Open Banking APIを導入しています。
APIはどこにでも存在し、すべてにとって重要です。
APIは、インターネットを裏で支える技術です。
Webサイトやモバイルアプリの利用、ATMなどの業務アプリの操作には、実際には数十〜数千回のAPI呼び出しが裏で行われています。
個々の呼び出しが、サービス全体のパフォーマンスや安定性に影響を及ぼす可能性があります。
応答が遅ければサービス全体が遅くなり、エラーが返されればサービスが正常に動作しなくなります。
自社サービスとそれが利用するAPIとの相互作用を理解することは、サービスのレジリエンスを高める上で極めて重要です。
APIを監視する方法はいくつかあります。
すべてのシステムが最低限行うべきことは、自社APIおよび外部APIの両方に対して、積極的な監視、測定、およびテストを行うことです。
API監視システムは以前から存在しています。
APIの到達性を確認する基本的なpingから、応答時間や機能の検証などを行う高度なマルチステップスクリプトによる積極的な監視まで、様々です。
より高度なAPI監視では、特定のAPIを意図的に遮断したり、エラーをシミュレートすることで、システム全体への影響を確認するカオスエンジニアリングの手法も取り入れられています。
APIのレジリエンスは不可欠です - その理由とは
現代のアプリケーションやシステムは、APIを通じて連携し、地理的に分散された環境や複数のクラウドをまたぎ、インターネット上の複雑な経路を経由しています。
そのため、従来のような単純な監視手法だけでは対応が難しくなっています。
従来のAPI監視では、重大なインシデントを見落とす可能性が高く、原因の特定にも不十分です。
最終的な目標は、障害にも強いレジリエントなAPIを構築することです。
レジリエンスを測る指標は以下のとおりです
- 到達性
- 自分のいる場所からそのAPIにアクセスできますか?(あるいはAPIの場合、その利用者がいる場所からアクセス可能ですか?)
- 可用性
- APIは機能していますか?つまり、期待された動作をしていますか?
- パフォーマンス
- APIは期待された時間内に応答しますか?
- 信頼性
- そのAPIが常に安定して動作すると信頼できますか?
次に、この指標をシステム内で使用されているすべてのAPIに適用してみましょう。
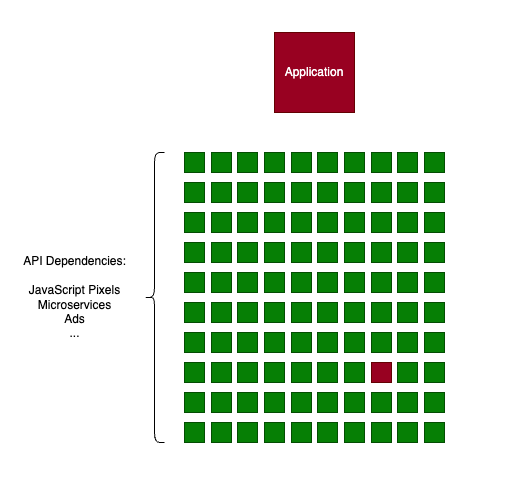
システムのレジリエンス = 使用中のすべてのAPIの中で最も低いレジリエンス

例を使って説明しましょう。
100個のAPIを持つシステムがファイブナイン(99.999%)の可用性を維持するためには、すべてのAPIがファイブナインの可用性を備えていなければなりません。
ただし、レジリエンスを考慮した設計を行えば、あるAPIが一時的に使えなくなってもシステム全体に影響を与えないようにすることは可能です。
そのためには、入念な設計と十分な検証が不可欠です。
この目標を念頭に置きながら、API監視に求められる要件を見ていきましょう。
基本的なAPI監視戦略に含むべき内容
これらは、すべてのAPI監視戦略に含めるべき基本的な機能です。
これらの機能は、チームが問題を検出し、可用性を確保し、運用レベルでパフォーマンスを検証するのに役立ちます。
- 応答時間
- APIがリクエストに応答するまでの時間を測定し、レイテンシの問題を特定します。
- エラー率
- 失敗したリクエストの割合を追跡し、異常やバグを検出します。
- スループット
- 特定の期間内に処理されたAPIリクエスト数を監視し、スケーラビリティを確認します。
- 稼働時間と可用性
- APIが継続的に利用可能であり、正常に機能していることを保証します。
- ロギング
- タイムスタンプ、イベント種別(例:エラー、警告)、メッセージを含むAPIイベントの詳細なログを収集し、トラブルシューティングや事後分析を支援します。
- アラート
- 事前に定義された閾値や異常(例:応答時間が200msを超える、エラー率が5%を超える)に基づいてアラートを設定します。
- 機能テスト
- APIエンドポイントが期待どおりの結果を返すかを検証します。
- CI/CD統合
- JenkinsやTerraformなどのツールと連携し、テストの自動作成・更新を実現する「Monitoring as Code」の機能です。
- 能動的監視
- テスト用リクエストを継続的に送信し、APIの応答状況を監視することで、障害を即座に発見します。
- スクリプティング
- Playwrightなどの標準的なスクリプト言語をサポートしており、特定ユーザ向けや複雑なAPIフローの検証が可能です。
- 履歴データ
- 前年同時期とのパフォーマンス比較のために、最低13ヶ月間のデータ保持が必要です。
- 高カーディナリティデータ分析
- ユーザIDやセッション単位の詳細なデータポイントを分析し、パフォーマンスの変化や異常を的確に把握します。
- カオス・エンジニアリング
- 使用が少ない時間帯や非本番環境で意図的にエラーを導入し、システムのレジリエンスを検証します。
現代のインターネット中心のAPI監視要件
現在のシステムには、単なる稼働チェックや応答時間の測定だけでは不十分です。
現代のAPI監視は、地理、インフラストラクチャ、ユーザ体験、外部依存性といった現実の複雑性に対応しなければなりません。
これらの機能は、基本的な監視では得られない、より深く価値ある情報を提供します。
- 必要な場所からの監視
-
多くの監視ツールはクラウド上のサーバにエージェントを配置していますが、これらは実際のシステムとは接続性やリソース、帯域幅が異なるため、地理的ルーティングやISPの混雑といった実環境の違いを見落としがちです。
システムがAPIを利用するすべての場所から、同様の特性を持つエージェントを用いて監視することが重要です。
また、中間サービスの配置場所も考慮する必要があります。
例えば、お客様向けAPIから全体のアプリケーションを監視するにはラストマイルのエージェントを、クラウド内の中間マイクロサービスはクラウドプロバイダから、データセンター内のバックエンドAPIは都市やISPに配置されたバックボーンエージェント、またはデータセンター内のエンタープライズエージェントを使うとよいでしょう。 - インターネットスタックの可視性
-
APIが応答しない、あるいは遅延していることを把握するだけでなく、その原因を突き止めることが重要です。
現代のAPI監視は、DNSの解決、SSL、ルーティングといったインターネットスタック全体にわたる影響要因を可視化します。
さらに、社内ネットワークやSASE(Secure Access Service Edge)の構成、ゲートウェイなどによって生じる遅延やパフォーマンスの変化も可視化できます。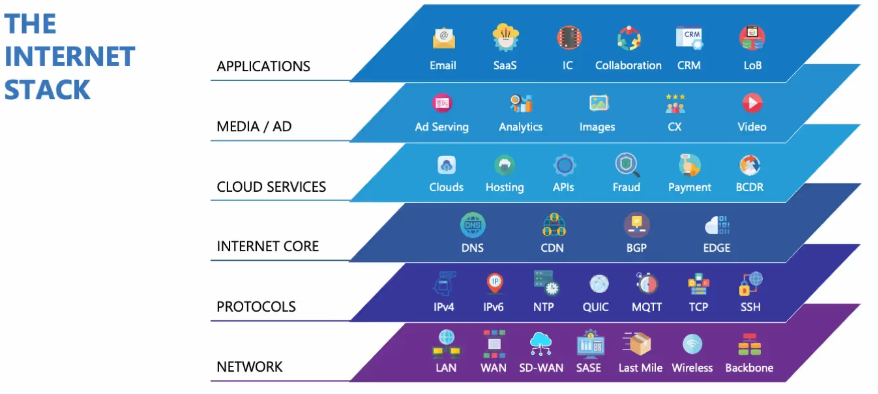
インターネットスタック - 認証
-
現代の監視システムでは、安全性の高いAPIに対して認証情報をハードコードするべきではありません。
そのため、シークレット管理、OAuth、トークンといった最新の認証方式をサポートすることが求められます。 - テスト中のコードトレーシング
- APIのテスト実行中にコードの実行経路をトレースし、アプリケーションの不具合や接続問題、データベースの異常など、サーバ側の課題を明らかにします。
- OpenTelemetry(OTel)サポート
- モダンなオブザーバビリティの実装においては、複数システム間でのデータ統合と共有を可能にする標準手法として、OTelへの対応が必須です。
- ユーザ体験へのフォーカス
-
APIは、システム全体のパフォーマンスを構成する一要素にすぎません。
例えば、決済APIは、オンラインショッピングにおける取引全体の中の一構成要素にすぎません。
重要なのは、取引全体がエンドユーザの視点でスムーズに機能することです。
理想的には、運用チームがエンドユーザから始まり、インターネット、ネットワーク、システム、API、さらにはコードトレーシングに至るまで、取引に関わるすべての依存関係を視覚的に把握できる状態が望まれます。 - 幅広いプロトコルのサポート
- 多くのAPIはHTTPベースのRESTを使用していますが、IPv4およびIPv6の両方のエージェントからのテストや、http/3やQUICといった現代的プロトコル、IoT用途のMQTT、時刻同期用のNTP、あるいは独自プロトコルのサポートも重要です。
従来型と現代型のAPI監視の違い
以下の表は、従来のAPI監視アプローチと、レジリエンスとユーザ体験をサポートする現代的なInternet Performance Monitoring(IPM)戦略の主な違いをまとめたものです。
| 機能 | 従来型API監視 | 現代型API監視(IPM) |
|---|---|---|
| 対象範囲 | サーバ中心のメトリクス | エンドユーザ体験とインフラストラクチャ全体 |
| プロトコルサポート | HTTP/S、RESTに限定 | HTTP/3、QUIC、MQTT、独自プロトコル |
| データの粒度 | 高カーディナリティのデータはあるが、サービス境界に限定されがち | 高カーディナリティのトレースとクロスシステムの相関(ユーザID、セッション) |
| 根本原因分析 | アプリ/サーバ層に限定 | インターネットスタック全体(DNS、SSL、ルーティングなど) |
| テストの観点 | クラウドデータセンター | ラストマイル、バックボーン、クラウド、無線、エンタープライズ知能エージェント |
| パフォーマンスの文脈 | コード内でのAPIのパフォーマンス | ユーザ体験を基準としたAPIのパフォーマンス |
| アラート手法 | エラー率に基づく閾値アラート | 体験スコアやXLOs(体験レベル目標) |
| 可視化 | コード中心のダッシュボード | システムに影響を与えるすべてを視覚的に表示 |
API監視の再考
クラウドが登場してからわずか15年であることは少々驚きです。
技術やシステムアーキテクチャが進化してきたように、監視も進化しなければなりません。
API監視も例外ではありません。
今日「自社所有」または「オンプレミス」と考えられているインフラストラクチャの多くは、実際にはコロケーションデータセンターにあり、DNSやSSLプロバイダーに依存し、2つ以上のISPに接続され、クラウドベースの認証システムやセキュリティプロバイダー、その他複数のAPIに依存しています。
「APMシステムではすべてが緑になっているのに、ユーザからは不満の声が続いている」といった声をよく耳にします。
「オンプレミス」のAPIだけを監視するシステムでは、インシデントを迅速に特定、診断、防止するための有用な根本原因情報を得ることはできません。
APIのレジリエンスを確保するために、企業はエンドツーエンドの可視性、積極的なアラート、そして自動的な復旧能力を備えた現代的な監視ソリューションへの投資が必要です。
API監視を近代化する準備はできていますか?
CatchpointのAPI Monitoringが、ユーザが期待するエンドツーエンドの可視性とレジリエンスをどのように実現するかをご覧ください。