
Zendeskの障害:プロアクティブな監視と迅速なインシデント対応の必要性
クラウド障害の連鎖を読む
2025年3月24日
著者: Kshantha Sagar
翻訳: 永 香奈子
この記事は米Catchpoint Systems社のブログ記事「Zendesk outage: A case for proactive monitoring and faster incident response」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
2025年3月20日、協定世界時(UTC)15時43分より、全世界のZendeskユーザが503「Service Unavailable(サービス利用不可)」エラーおよび5xx系のサーバ側の問題に直面し、重要なサポートツールおよびコミュニケーションチャネルへのアクセスが妨げられました。
即時の緩和措置により中核サービスは安定化しましたが、断続的な問題は24時間以上続き、マルチポッドインフラ障害の複雑さが浮き彫りになりました。
障害のタイムライン
- UTC 15時29分: Zendeskの内部チームが、ユーザからのアクセス障害報告を確認しました。
- UTC 15時50分: 根本原因が、複数のサービスポッドに影響を与える広範な503エラーであると特定されました。
- 2025年3月21日 UTC 10時59分: Zendeskの内部チームが、ユーザからのアクセス障害報告を確認しました。
503 Service Unavailableの応答が、障害の根本原因として即座には認識されませんでした。
この遅れにより、Zendeskは障害の範囲と影響を迅速に把握することができず、サービスの復旧および顧客対応のプロセスが遅れる結果となりました。
Zendeskがダウンしたとき、企業はその影響を痛感した
Zendeskの障害により、顧客サポート、営業、社内コラボレーションのために同プラットフォームに依存している何千もの企業の業務が麻痺しました。
重要なプロセスが中断され、チームは迅速かつ効果的な顧客サービスの提供に苦慮しました。
以下は、主な影響の一部です。
#1 複数のポッドにわたるアクセス障害
多くのユーザが5xx系エラーに直面し、これはサーバ側の問題を示していました。
小売業から医療業界まで、あらゆる業界のユーザが突然Zendeskポータルにアクセスできなくなりました。
サポートチームはチケットの閲覧、ケースの更新、顧客履歴へのアクセスができませんでした。
#2 サービスの劣化
一部のサービスは再起動に追加の時間を要し、それにより断続的なエラーが発生しました。
これらのエラーは、顧客対応に追われる企業にとって最も困るタイミングで起こることが多かったのです。
その結果、サポート担当者は不安定なアクセス環境に悩まされ、業務を一時中断したり、やり直したりせざるを得ませんでした。
#3 コミュニケーションチャネルへの影響
Zendeskの主要なサポートツールは、障害発生中の広範な時間帯でオフラインとなり、対応時間や業務連携に支障をきたしました。
企業のWebサイト上で顧客と直接やり取りするために使用されていたWebウィジェットもダウンし、即時対応や迅速な自己解決を期待していたユーザを苛立たせました。
#4 復旧までの長期化
Zendeskは「大部分のサービスが3月21日までに復旧した」と報告したものの、断続的なエラーは24時間以上続きました。
このため、多くの企業は手動の業務プロセスへの切り替えを余儀なくされた可能性があります。
Zendeskよりも先に障害を検知したInternet Sonar
CatchpointのInternet Sonarは、UTC時間の午前3時22分に障害を検知しました。
これはZendeskの社内アラートより21分早いタイミングでした。
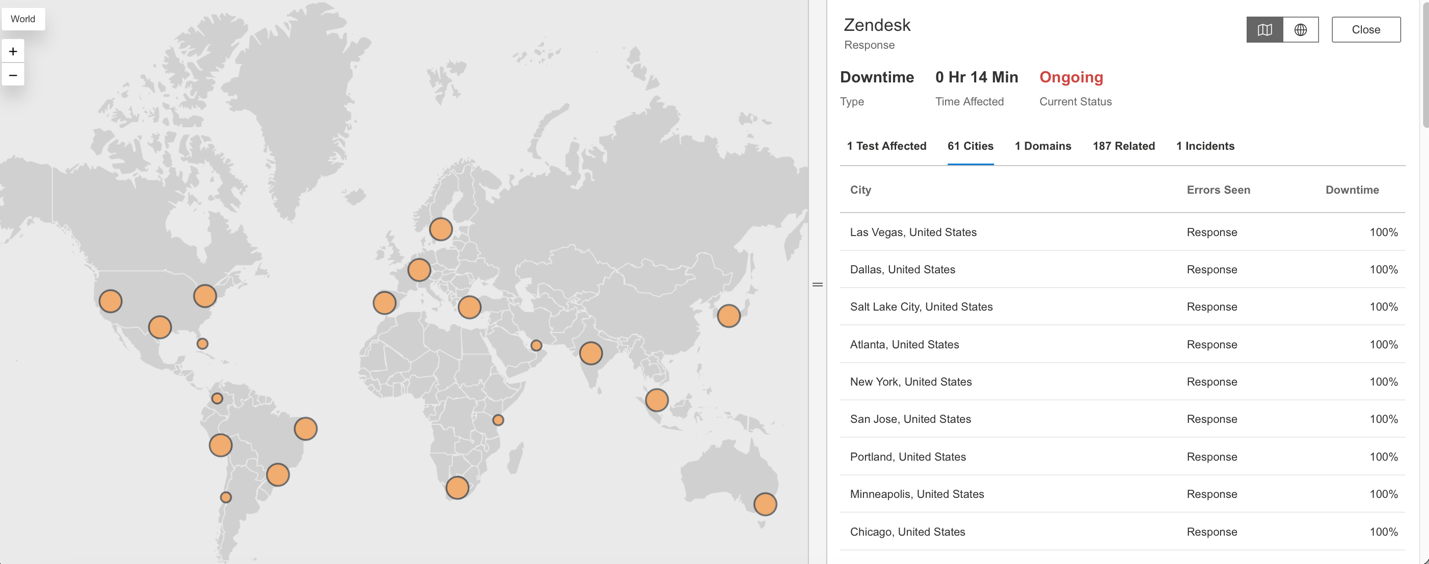
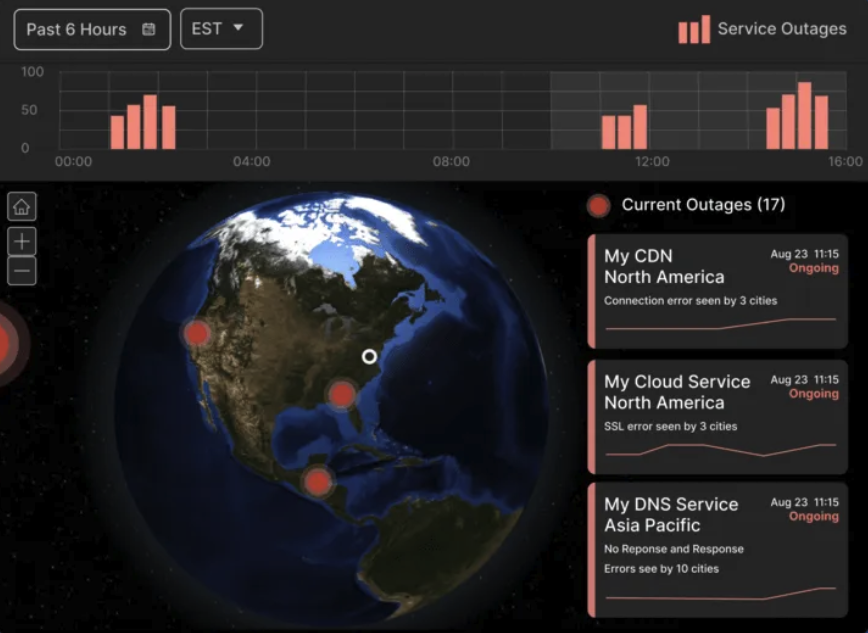
Internet Sonarのダッシュボードには、Zendeskの障害が複数の世界各地に影響を与えている様子が表示されています。
複数の都市で100%のダウンタイムが報告されました。
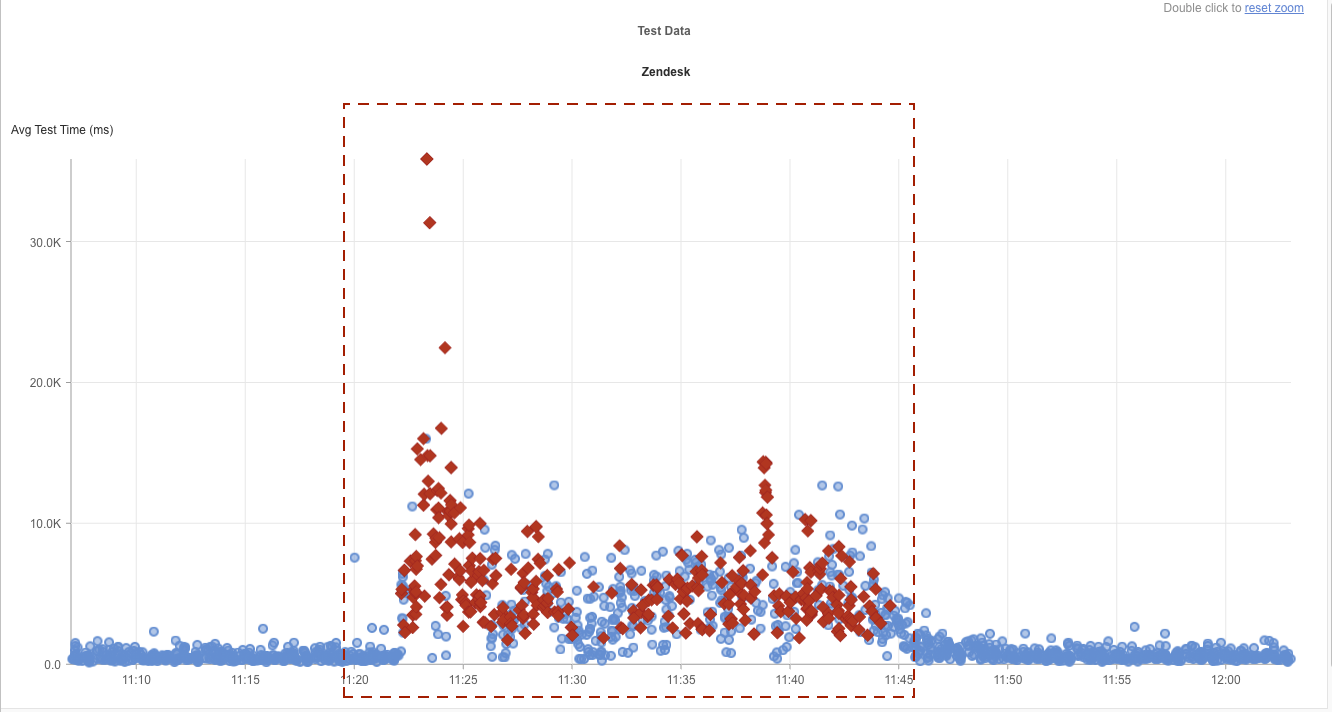
上記のInternet Sonarの散布図は、Zendeskの障害を可視化したものです。
11時22分頃から、テスト失敗の急増(赤いマーカー)を示しています。
失敗の集中は、広範囲にわたるサービス障害を示しています。
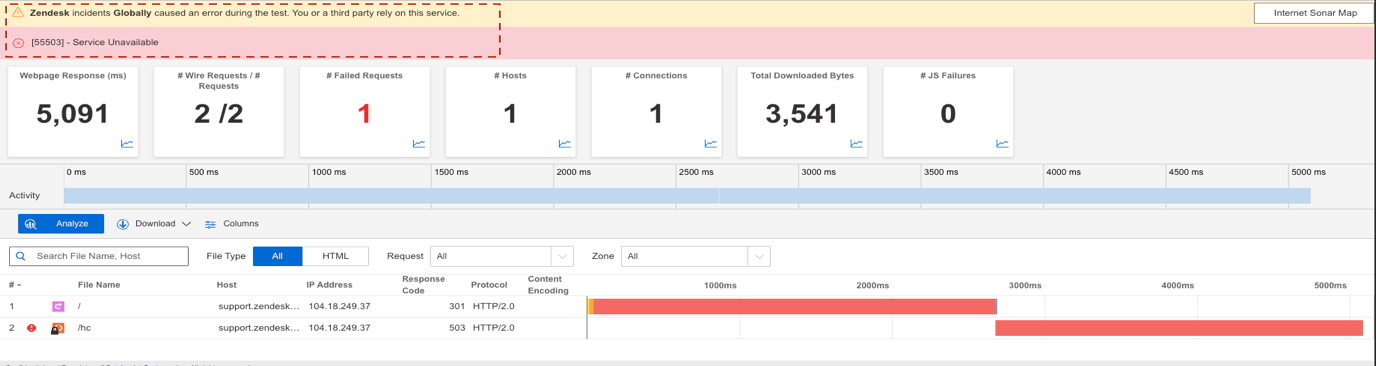
Zendeskの障害から得られる主な教訓
Zendeskの障害は、インターネットのレジリエンスを維持するためには、リアルタイムの可視性、プロアクティブな監視、そしてサードパーティへの依存関係を深く理解することがいかに重要であるかを浮き彫りにしています。
1. 根本原因分析の遅延によるコスト
Zendeskの社内チームは、CatchpointのInternet Sonarによってすでに検出されていた503エラーとユーザーレポートとを関連付けるのに21分を要しました。
これは一見すると長い時間ではないように思えるかもしれませんが、ダウンタイムの1分ごとに収益の損失、顧客の不満、業務の混乱が発生します。
問題の特定に時間がかかればかかるほど、修復にも時間がかかります。
どこで、なぜ問題が発生しているのかを即座に可視化できない場合、ITチームは問題が社内要因なのか、サードパーティによるものなのかを判断しようと、「ウォールーム」での議論や責任の押し付け合いに貴重な時間を浪費することになります。
2. インターネットスタックの独立したプロアクティブな監視は不可欠
いかなる組織においても、自社のデジタルエコシステムに対する独立したプロアクティブな可視性なしに運用を続けることは許されません。
そこで役立つのが、Catchpointのインターネットパフォーマンスモニタリング(IPM)ツール群です。
Internet Sonarは、リアルタイムかつ独立したインターネットの健全性データを提供することで、推測を排除する強力なツールです。
Internet Sonarを使用すれば、サードパーティに障害が発生した際、その場所、継続時間、そして自社への影響の可能性まで把握できます。
Internet Sonarは、人々がTwitterで投稿した後に「サイトが落ちた」と知らせるようなものではありません。
つまり、責任の押し付け合いやウォールームでの混乱は不要で、生産性やユーザー体験に影響を与える可能性のあるサードパーティのインシデントを先回りして把握できる、明確でインテリジェントかつ信頼性の高い、インターネット健全性情報を得ることができます。
3. マルチポッドインフラに潜む課題
Zendeskの障害は、マルチポッドアーキテクチャの脆弱性も明らかにしました。
1つのポッドでの障害が、複数のリージョンにわたって問題を連鎖的に引き起こしたのです。
こうしたアーキテクチャは、スケーラビリティや冗長性を目的として設計されていますが、ひとたび問題が発生すると、その複雑さが原因でダウンタイムが長引くリスクがあります。
今回のケースでは、初期復旧の後も断続的な障害が24時間以上続き、サービスの完全復旧が妨げられました。
Zendeskのようなクラウドベースのアプリケーションに依存している企業にとって、これは、サードパーティのインフラ依存関係を深く可視化する必要性を改めて浮き彫りにする出来事です。
- どこで障害が発生しているのか。
- それが相互接続されたシステムにどのような影響を及ぼしているのか。
- 復旧プロセスにどれくらいの時間がかかる可能性があるのか。
CatchpointのInternet Stack Mapは、自社のデジタルサービスおよびそれが依存しているサービスの健全性をライブで可視化することで、こうした課題への対応を支援します。
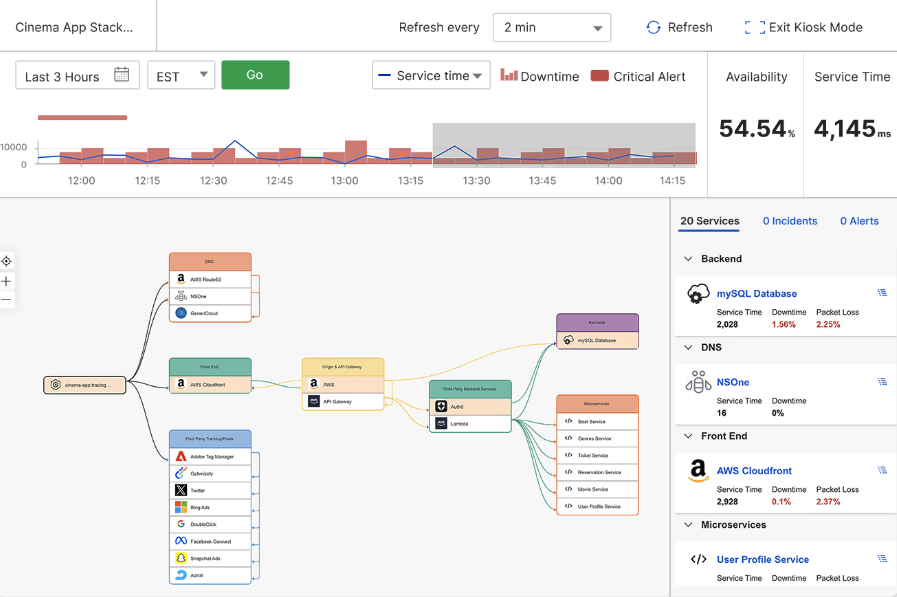
サードパーティの依存関係を自動的に検出することで、組織が自社のデジタルエコシステム全体の健全性を一目で把握できるよう支援します。
いずれかのコンポーネントに障害が発生した場合には、それが明確にハイライト表示されるため、根本原因の分析がスムーズに行えます。
障害の防止についてさらに詳しく知りたい方は、当社のガイドをご覧いただくか、ガイド付きプロダクトツアーでCatchpointをぜひご体験ください。